这里给大家分享用于Pandas中合并数据的 5 个最常用的函数。这样大家以后就可以了解它们的差异,并正确使用它们了。
在文章开始之前,我们需要创建两个简单的 DataFrame 对象。
import pandas as pd
df0 = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
df1 = pd.DataFrame({"c": [2, 3, 4], "d": [5, 6, 7]})

1. concat
concat 函数字面就是就是连接的意思,它可以帮我们横向或者纵向合并数据。
当你纵向合并数据时,需要将轴axis指定为0,这实际上也是默认值。
pd.concat([df0,
df1.rename(columns={"c": "a", "d": "b"})],
axis=0)
当你横向合并数据时,具体操作如下所示。
pd.concat([df0, df1], axis=1)
默认情况下,当我们横向合并数据(沿列)时,Pandas其实是按照索引来连接的。当两者的索引不相同时,就会用 NaN 填充不重叠的,举个例子如下所示。
df2 = df1.copy()
df2.index = [1, 2, 3]
pd.concat([df0, df2], axis=1)
这只是个小例子,如果希望它们不受索引的影响,可以先重置索引再执行concat连接。
pd.concat([df0.reset_index(drop=True),
df2.reset_index(drop=True)],
axis=1)
重置索引后,df0 和 df2 的索引就变得一致了。
2. join
与 concat 对比,join 专门用于使用索引连接 DataFrame 对象之间的列。
df0.join(df1)
当索引不同时,join连接默认保留来自左侧 DataFrame 的行。右侧 DF 中没有左侧 DF 中匹配索引的行,会被删除,如下所示:
df0.join(df2)
此外,还可以设置 how 参数,这点与SQL的语法一致。
# 右连接,使用 df2 的索引
df0.join(df2, how="right")
# "outer" 外连接
df0.join(df2, how="outer")
# "inner" 内连接(交集)
df0.join(df2, how="inner")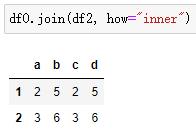
3. merge
与join相比,merge更通用,它可以对列和索引执行合并操作。
基于列的合并,可以这样操作。
df0.merge(df1.rename(columns={"c": "a"}),
on="a", how="inner")
on 参数定义两个 DataFrame 对象将合并到哪些列。当然,也可以分别指定左侧 DataFrame 和右侧 DataFrame 的合并列,如下所示。
df0.merge(df1, left_on="a", right_on="c")
除了 a 和 c 的单独列之外,它的结果与之前的合并几乎相同。这里,额外提两个特殊参数:笛卡尔积、使用后缀。
3.1. 笛卡尔积
how 参数设置为cross,构成笛卡尔积。是指两个数据框中的数据交叉匹配,出现n1*n2的数据量,具体如下所示。
df0.merge(df1, how="cross")
3.2. 使用后缀
当两个 DataFrame 对象有同名的列,且想保持同时存在,就需要添加后缀来重命名这两列。默认情况下,左右数据框的后缀是“_x”和“_y”,我们还可以通过suffixes参数自定义设置。
df0.merge(df1.rename(columns={"c": "a", "d": "b"}),
on="a", how="outer", suffixes=("_l", "_r"))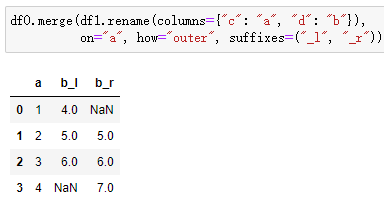
4. combine
combine 函数在两个 DataFrame 对象之间执行按列合并,它与之前的方法还是有很大不同的。combine 的特殊之处,在于它接受一个函数参数。此函数采用两个系列,每个系列对应于每个 DataFrame 中的合并列,并返回一个系列作为相同列的元素操作的最终值。听起来很混乱?
让我们举个例子,看一下:
def taking_larger_square(s1, s2):
return s1 * s1 if s1.sum() > s2.sum() else s2 * s2
df0.combine(df1.rename(columns={"c": "a", "d": "b"}), taking_larger_square)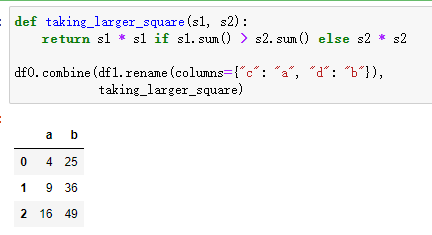
自定义的 take_larger_square 函数对 df0 和 df1 中的 a 列以及 df0 和 df1 中的 b 列进行操作。在两列 a 和两列 b 之间,taking_larger_square 取较大列中值的平方。
在这种情况下,df1 的 a 列和 b 列将作为平方,产生最终值,如上面的代码片段所示
5. append
回顾前文,我们讨论的大多数操作都是针对按列来合并数据。
如果按行合并(纵向)该如何操作呢?append 函数专门用于将行附加到现有 DataFrame 对象,创建一个新对象。我们先来看一个例子。
df0.append(df1.rename(columns={"c": "a", "d": "b"}))
上面的操作是不是很眼熟?就跟第一个方法concat的实现效果一致。
不过除了逐行拼接DataFrame,append还可以附加 dict 字典对象,这种方法更加灵活,具体如下所示:
df0.append({"a": 1, "b": 2}, ignore_index=True)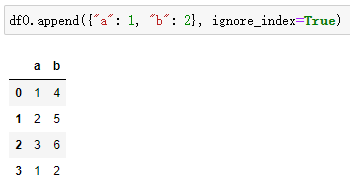
上面显示了一个简单的例子。请注意,您必须将 ignore_index 设置为 True,因为字典对象没有 DataFrame 可以使用的索引信息。
6. 小结
总结一下,我们今天重新学习了 Pandas 中用于合并数据的 5 个最常用的函数。他们分别是:
- concat[1]:按行和按列 合并数据;
- join[2]:使用索引按行合 并数据;
- merge[3]:按列合并数据,如数据库连接操作;
- combine[4]:按列合并数据,具有列间(相同列)元素操作;
- append[5]:以DataFrame或dict对象的形式逐行追加数据。
7. 参考资料
-
[1] concat: https://pandas.pydata.org/docs/reference/api/pandas.concat.html
-
[2] join: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.join.html#pandas.DataFrame.join
-
[3] merge: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html#pandas.DataFrame.merge
-
[4] combine: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.combine.html
-
[5] append: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append