1. 通信方式及IP类型
Anycast与Multicast,Unicast,Broadcast是四种不同的IP通信方式。按照通信方式,也可以将我们熟知的IP地址类型分为如下几种:Unicast IP,Multicast IP,Broadcast IP与Anycast IP。
1.1. Unicast IP
在客户端与媒体服务器之间需要建立一个单独的数据通道,从一台服务器送出的每个数据包只能传送给一个客户机,这种传送方式称为单播。指网络中从源向目的地转发单播流量的过程。单播流量地址唯一。每个用户必须分别对媒体服务器发送单独的查询,而媒体服务器必须向每个用户发送所申请的数据包拷贝。这种巨大冗余首先造成服务器沉重的负担,响应需要很长时间,甚至停止播放;管理人员也被迫购买硬件和带宽来保证一定的服务质量。文字单播方式下,只有一个发送方和一个接收方。与之比较,组播是指单个发送方对应一组选定接收方。
单播IP,IP地址和主机是一一对应关系。如下图,红色为数据包发送端,而绿色节点为数据包接收端。
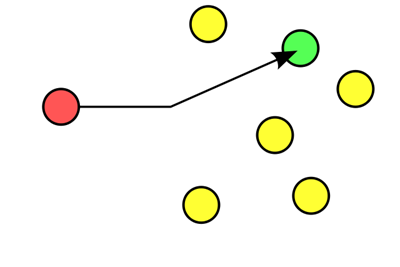
当数据包发送给某一个特定IP地址时,全局下仅有一个数据包接收主机。此为Unicast。
1.2. Multicast IP
Multicast 的中文译名是多播/多播,它是指网络中一个节点发出的信息被多个节点收到。实际上,在数据链路层和网络层都有Multicast,通常所说的Multicast大多是针对IP的。这种技术用于多媒体应用、多用户交互(如聊天室)、软件分发等,相比与传统的Unicast可以大大提高效率。在子网内实现 Multicast 较为简单,跨越子网时需要路由器、网关等设备的支持。
组播IP,组播IP拥有特定的IP地址段,当数据包发送给此组播IP地址后,组内成员都能收到此数据包的一份拷贝。如下图,红色为数据包发送端,而绿色节点为数据包接收端。当数据包发送给某一个特定组播IP地址时,同时存在多个数据包接收端。
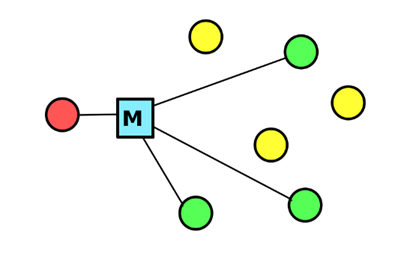
1.3. Broadcast IP
广播IP,任意Unicast单播网段中最后一个IP地址。数据包发送给此地址会扩散给全广播域的成员。
如下图,红色为数据包发送端,而绿色节点为数据包接收端。
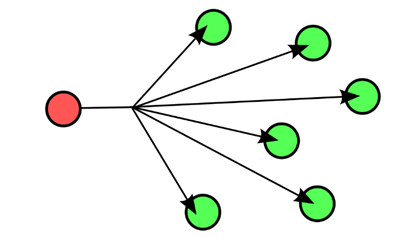
当数据包发送给广播IP地址时,所有成员均为数据包接收端。
1.4. Anycast IP
Anycast中文称为任意播。集Multicast和Unicast的特性于一身。从宏观上来说,Anycast类似于Multicast,同一种类型的数据流同时存在多个接收者。从微观上来说,Anycast又有着Unicast的唯一性。每一个单独的IP会话都能够找到唯一的源主机和目标主机。
Anycast IP,是集Multicast和Unicast特性于一身的特殊IP地址类型。Anycast中文称为任意播。
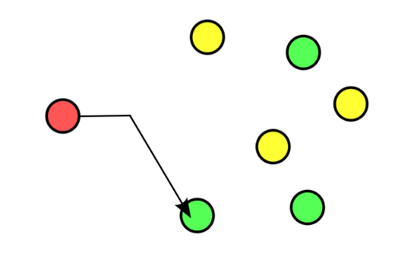
从宏观上来说,Anycast类似于Multicast,同一种类型的数据流同时存在多个接收者。而从微观上来说,Anycast又有着Unicast的唯一性。每一个单独的IP会话都能够找到唯一的源主机和目标主机。
2. anycast概述
说起Anycast,并不是在IPv6标准中突然出现的概念,早在很久很久以前,业界就针对IPv4提出了Anycast的说法,只不过相对而言,IPv6在操作上将其标准化了而已,如果说IPv4年代的Anycast标准只是 建议 ,那么IPv6的Anycast就是规定了些许 MUST , MAY。建议阅读:
- RFC1546-Host Anycasting Service:https://tools.ietf.org/html/rfc1546
- RFC3513:IPv6 Addressing Architecture :https://tools.ietf.org/html/rfc3513#section-2.6
Anycast 的定义是: 当一个单播地址被分配到多于一个的接口上时,发到该接口的报文被网络路由到由路由协议度量的“最近”的目标接口上。 Anycast 允许源结点向一组目标结点中的一个结点发送数据报,而这个结点由路由系统选择,对源结点透明;同时,路由系统选择“最近”的结点为源结点提供服务,从而在一定程度上为源结点提供了更好的服务也减轻了网络负载。正是Anycast 这一通信模式的特点,使它在IP网络中具有了应用前景。
2.1. Anycast技术特点
首先,分布的服务共享相同的IP地址,同时在IP层进行透明的服务定位,这使得各种网络服务特别是应用层服务具有更强的透明性,比如DNS(Domain Name System,域名系统),在IPv6网络中它可以共享一个熟知的IP地址,用户不需要特殊配置也不用关心访问的是哪一台DNS服务器;其次,路由系统选择了“最近”的服务,缩短了服务响应的时间,同时减轻了网络负载;最后,相同的服务在网络上冗余分布,路由系统可以提供机制选择负载相对轻的带宽相对高的路径来转发报文,这样就给用户带来了两个方面的好处:
- 减弱了分布式拒绝服务攻击(DDoS:Distributed Denial of Service)对用户带来的影响。当 Anycast 组中某一个成员或者几个成员受到攻击时,负责报文转发的路由器可以根据各个组成员的响应时间来决定报文应该转发到哪个成员上,这样受到攻击的成员由于没有响应,所以报文就不会被转发到那里,同时,由于 Anycast 提供的服务访问透明性,组成员也相对较难受到DDoS攻击。
- 减弱了网络拥塞给用户带来的影响。同上面的道理,当 Anycast 的某些组成员处在拥塞的网段时,它的响应时间就较长,报文可以被转发到响应较好的成员那里。
2.2. IP相同疑虑
本质上, Anycast就是将同一个IP地址配置在不同的主机网卡上,然后利用各种选路机制欺骗源主机的一种通信方式。怎么能让互联网的多个主机用同一个IP,这岂不是IP地址冲突了?
IP地址存在的目的就是为了指挥路由器选路,最终将数据包路由到目的地,那么IP地址冲突的结果是什么?
IP地址冲突不是问题,路由冲突才是!!
IP地址冲突只有导致路由器的路由冲突(be confusing)的时候才有问题。
比如路由器R上配置的下面的两条路由:
1.1.1.1 nexthop 2.2.2.2 dev e2
1.1.1.1 nexthop 3.3.3.3 dev e3请问一个去往目的地1.1.1.1的数据包到达路由器R之后到底是从e2走呢,还是从e3走呢?这就是问题。但是同样的路由,加一个约束就不会有问题:
1.1.1.1 nexthop 2.2.2.2 dev e2 metric 100
1.1.1.1 nexthop 3.3.3.3 dev e3 metric 10路由器会毫不犹豫地将去往1.1.1.1的数据包从e3发出!
- 每一个服务器主机处在不同的地理位置,他们之间不在同一个广播域内。所以把所有主机配置成相同的IP地址并不会引起我们日常所见的IP地址冲突。
- 光靠配置相同的IP地址是不够的,我们还需要借助强大的BGP帮忙。
- 通过BGP,各个站点向Internet宣告相同的Anycast IP地址。
2.3. 优缺点
-
优点
- Anycast可以零成本实现负载均衡,无视流量大小。
- Anycast是天然的DDOS防御措施,体现了大事化小,小事化了的解决方法。
- 部署Anycast可以获得设备的高冗余性和可用性。
- Anycast适用于无连接的UDP,以及有连接的TCP协议。
-
缺点
- Anycast严重依赖于BGP的选路原则,在整个Internet网络拓扑复杂的情况下,会导致次优路由选择。
3. BGP AnyCast
通过结合BGP协议,变相提高了Anycast的使用广度和深度。Bgp+anycast是多个主机使用相同ip地址的一种技术,当报文发给该地址时,根据路由协议,选择最近(跳数最少)的主机服务。因此,当某台主机服务量大,或者被攻击,到该主机的距离变长,使得报文被发送给另外的主机。所以,bgp+anycast天然支持负载均衡和抵抗ddos攻击
3.1. 原理
BGP anycast就是利用一个(多个) as号码在不同的地区广播相同的一个ip段。
利用bgp的寻路原则,短的as path 会选成最优路径(bgp寻路原则之n),从而优化了访问速度。
其实bgp anycast是不同服务器用了相同的ip地址。阿里的DNS 就是使用了BGP AnyCast。“其实bgp anycast是不同服务器用了相同的ip地址。” 言简意赅啊!
DNS多点部署IP Anycast+BGP实战分析, 根据这个网页资料,我对BGP anycast 的理解是IP anycast + bgp, ip anycast(ip任播) 本身就是多个主机使用同一个IP地址(该地址即这一组主机的共享单播地址)的一种技术,当发送方发送报文给这个共享单播地址时,报文会根据路由协议路由到这一组主机中离发送方最近的一台,所以这个技术也可以用来做负载均衡。
3.2. BGP的结合实践
使用BGP,可实现ip不冲突;
- 设置多个服务器IP为相同IP,如1.1.1.1
- 通过各个站点的BGP对互联网宣告1.1.1.0/24的网段
- 以上步骤完成以后,互联网路由表针对1.1.1.1/24会有三个不同的出口路由器,分别是北京,上海,广州(举例)
- 因为所有用户都使用1.1.1.1作为他们的服务器,不同地区的用户根据就近原则,选择相应的主机。
3.3. ipv6配置和实现
很少有资料讲 如何在Linux上配置IPv6的Anycast 的,这一次可能我又占了坑。
其实很简单,只要开启IPv6的转发即可:
sysctl -w net.ipv6.conf.all.forwarding=1这个时候,你就会在/proc/net/anycast6看到内容:
[root@localhost src]# cat /proc/net/anycast6
3 enp0s8 fe800000000000000000000000000000 1
4 enp0s9 fe800000000000000000000000000000 1
4 enp0s9 240e0918800300000000000000000000 1我在enp0s9上配置了如下的IPv6地址:
[root@localhost src]# ip -6 addr ls dev enp0s9
4: enp0s9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qlen 1000
inet6 240e:918:8003::3f5/64 scope global
valid_lft forever preferred_lft forever
inet6 fe80::eb7c:b2da:7088:3c38/64 scope link noprefixroute
valid_lft forever preferred_lft forever所以说,什么都不用干,Linux内核自动帮我生成了其对应的Anycast地址,对应RFC3513的2.6.1 Required Anycast Address格式:240e:918:8003::
按照上面一个小节最后的例子,我们知道,这个 240e:918:8003:: 是可以被邻居发现而解析的,而我们知道,IPv6的邻居发现使用的是组播地址,其组播构成规则详见:
RFC3513-2.7 Multicast Addresses: https://tools.ietf.org/html/rfc3513#section-2.7
对应组播地址:
FF02::1:FF00:0000/104 Solicited-Node Address [RFC3513] -RFC4291对其进行了增强更新
Solicited-Node Address: FF02:0:0:0:0:1:FFXX:XXXX
Solicited-node multicast address are computed as a function of a
node’s unicast and anycast addresses. A solicited-node multicast
address is formed by taking the low-order 24 bits of an address
(unicast or anycast) and appending those bits to the prefix
FF02:0:0:0:0:1:FF00::/104 resulting in a multicast address in the
rangeFF02:0:0:0:0:1:FF00:0000
to
FF02:0:0:0:0:1:FFFF:FFFF
我们针对Linux的如上配置确认一下:
[root@localhost src]# cat /proc/net/igmp6
1 lo ff020000000000000000000000000001 1 0000000C 0
1 lo ff010000000000000000000000000001 1 00000008 0
...
# 下面这个便是!
4 enp0s9 ff0200000000000000000001ff000000 2 00000004 0
...将Anycast地址作为默认网关发送数据,最终邻居解析的时候,只要发送到组播地址 ff02::1:FF00:: 就可以解析出该网段上的Anycast地址的MAC地址信息,然后 取第一个到达的作为邻居 即可!
上面关于组播的设置,请看 addrconf_join_anycast 函数:
static void addrconf_join_anycast(struct inet6_ifaddr *ifp)
{
struct in6_addr addr;
if (ifp->prefix_len >= 127) /* RFC 6164 */
return;
ipv6_addr_prefix(&addr, &ifp->addr, ifp->prefix_len);
if (ipv6_addr_any(&addr))
return;
ipv6_dev_ac_inc(ifp->idev->dev, &addr);
}其中,ipv6_dev_ac_inc 值得观摩!
配置也配好了,那么我们找两台机器练一练手吧。
这次我部署的另外一个机器是Windows 7系统,顺便玩一下netsh。这台Win7系统机器和我们的Linux Rh7.2直连,拓扑我就不画了,非常简单。我只是把Win7上的地址配置发布出来。
很简单,Win7上配置一个 240e:918:8003::/64* 同网段的IPv6地址:
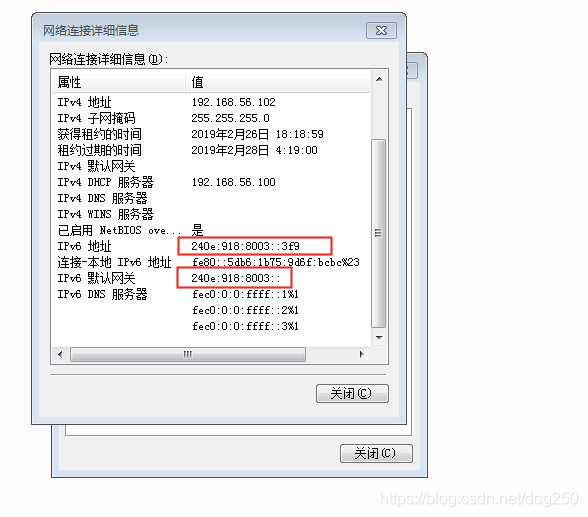
这个时候,将Win7的默认网关设置成 240e:918:8003::* 这个Linux上使能的Anycast地址,看看如何通信。
按照惯例,ping一下这个 240e:918:8003::* 地址:
不通!
在Linux上抓包,发现是有回复ICMPv6 Echo Reply的,只是说回复的源IP地址不是Win7期望的Anycast地址,而是Linux上enp0s9网卡的地址,这正是印证了 An anycast address must not be used as the source address of an IPv6 packet. 这句话!
我很好奇Linux内核是怎么做到 不让Anycast地址作为源地址的 ,ping不行,TCP的Telnet也不行…其实看一下代码就完全明白了。
先看下Telnet为什么完全就没有SYN-ACK回复:
再看看为什么ping回复的时候用的不是Anycast地址,而是选择了网卡上配置的地址:
这个关于源地址选择的细节,详见RFC3484以及我的前一篇闲谈:
- Default Address Selection for Internet Protocol version 6 (IPv6) :https://www.ietf.org/rfc/rfc3484.txt
- 闲谈IPv6-源IP地址的选择(RFC3484读后感) :https://blog.csdn.net/dog250/article/details/87815123
脉络理清了之后,我们来反一下,让Win7主机配置Anycast。
我特意没有按照RFC的规定,去配置了一个非标准的Required Anycast Address,且看:

配置方法如下:

我并没有让低n-bit为全0,竟然成功了,这说明Win7并没有严格按照RFC的规范行事,它完全是手动的。
那么好,我在Linux上去ping这个Win7的Anycast地址:
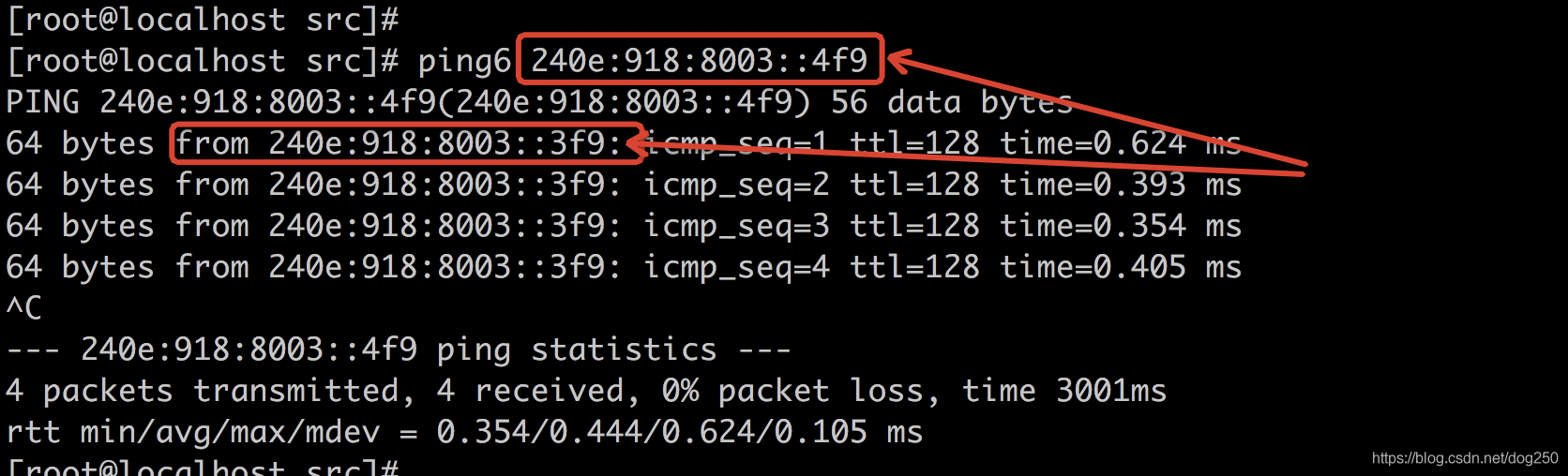
得到了Win7的回复,然而源地址不是Win7的Anycast地址,却是Win7的物理网卡 本地连接 3 上配置的IPv6地址。这依然印证了 An anycast address must not be used as the source address of an IPv6 packet. 这句话。
只是说,Win7对Anycast地址 并没有严格遵循subnet后面的低bits均为0的约束 ,即Win7没有实现严格的Required Anycast Address!
3.4. 总结
- IPv6的Anycast:
- 以往IPv4的规则在IPv6 RFC约束下依然适用
- 独添了subnet-Anycast,见上文
- Anycast总结为:
- 广义的Global Anycast-作用于IPv4/IPv6
- 狭义的IPv6 subnet Anycast-作用于IPv6
此外,RFC2526又规定了 保留的Anycast地址 用于不同的目的:
RFC2526-Reserved IPv6 Subnet Anycast Addresses :https://tools.ietf.org/html/rfc2526
本文不涉及RFC2526的内容,但是提醒注意,仅此而已。
4. AnyCast应用场景
在企业网络环境中,Anycast不太常见,其主要应用于大范围的DNS部署,CDN数据缓存,数据中心等场景。
4.1. DNS
DNSPod Public DNS+的架构是怎么样的?
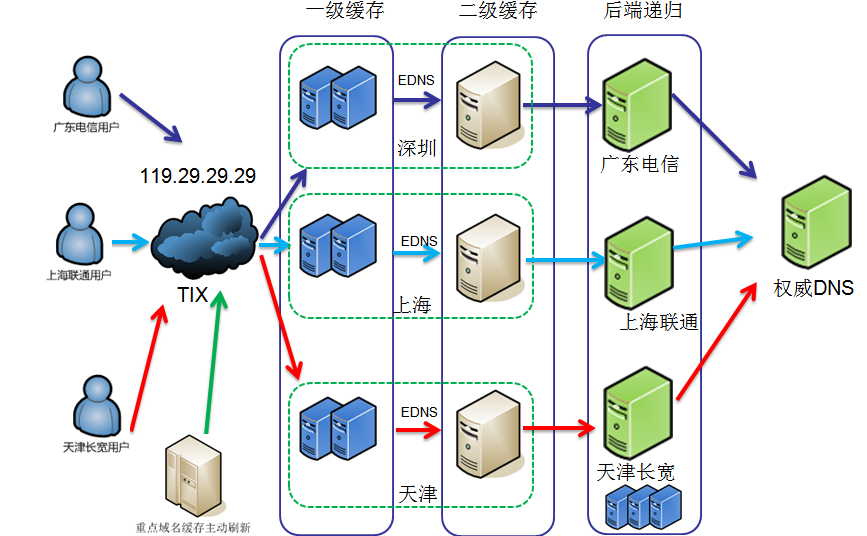
4.2. Load-balancing 负载均衡以及系统冗余性
4.2.1. 场景描述
为了阐明使用Anycast和负载均衡,以及冗余性的关系,特举例如下:
假设我们现在有三个DNS服务器站点,地点分别在北京,上海,广州。他们服务了全国的DNS解析服务。
按照一般的解决方案,为了实现三个DNS服务器负载均衡,可能有人会考虑到使用硬件负载均衡设备,例如常见的F5负载均衡设备等。
但若使用硬件负载均衡,随之带来的问题有:
- 网络流量瓶颈,所有有流量都需要先通过负载均衡设备,而硬件设备本身的吞吐量决定了整个网络环境的吞吐量。
- 高昂的硬件成本,为了实现全国的流量负载均衡,试想需要多大吞吐量的硬件设备。硬件吞吐量越大,购买成本就越高。
而通过Anycast技术,无需要借助任何第三方负载均衡器,就可以轻松达到负载均衡的效果,同时还提供了冗余和高可靠性。
4.2.2. 实施方案
通过配置三个DNS站点的服务器IP为相同IP,例如1.1.1.1/32。然后通过各个站点的BGP对互联网宣告1.1.1.0/24的网段。
(注:为什么要宣告/24,而不是/32? 。因为在Internet里面,为了减小全球Internet路由表尺寸,默认情况下运营商只接受小于等于/8,而大于等于/24的网段宣告进入互联网。)
以上步骤完成以后,互联网路由表针对1.1.1.1/24会有三个不同的出口路由器,分别是北京,上海,广州。
重点来了,因为所有用户都使用1.1.1.1作为他们的DNS服务器。
以东北的用户来说,哪一台DNS服务器会给东北的用户提供解析呢?
答案就是:就近原则!
4.2.3. 数据包在网络中的路由细节
当用户的DNS请求到达运营商的宽带路由器以后,运营商的路由器会根据BGP的选路原则选择到达1.1.1.1的最优路径。
例如,在用户宽带运营商和DNS服务器Internet运营商相同的情况下,最终会以IGP metric为关键因素来决定哪个DNS服务器给用户提供服务。
而IGP的 Metric某种程度上就是物理距离的代表。
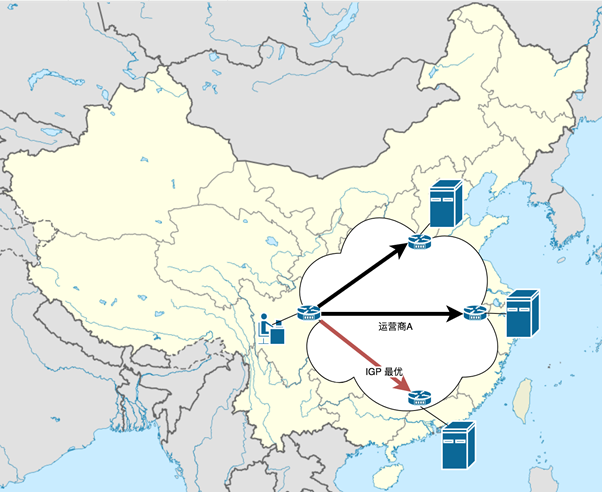
如上图,四川的宽带路由器通过查看BGP路由,发现1.1.1.1出口最优路由是在广州。那么四川用户的DNS数据包将被发送给广州的DNS服务器。
同理,东北的用户DNS解析将会被发往北京的DNS服务器,而江南一带的则是上海DNS服务器负责。
4.2.4. 万一出现故障怎么办?
如果三台DNS服务器中某一台出现故障,例如广东DNS服务宕机。BGP协议会立即停止通告此1.1.1.0/24的网段。Internet 路由表将会只有北京和上海的DNS可供选择。
此时原广东DNS服务的用户将再次根据“就近原则”选择其他DNS服务器,例如上海DNS。
从而达到业务的平滑迁移和服务的高可用性。
基于以上的分析,我们很容易就得出如下结论:
全国用户最终会根据距离DNS服务器的远近来判断使用哪个DNS服务器做域名解析。
从DNS角度来说,正因为不同的地理位置用户会根据就近路由判断,从而选择不同的DNS服务器,最终会使三台DNS服务器达到负载均衡的效果。
若其中某一个节点出现故障以后,业务会立即迁移到其他可用的节点上,从而避免网路服务故障。完全不需要人工干预。
以上就是Anycast在负载均衡中的用途说明。
4.3. 防范DDOS攻击
4.3.1. 场景描述
相信很多在运营商工作的朋友都非常讨厌DDOS攻击。
当DDOS发生时,10G或100Gbps的流量突然蜂拥而来,占用运营商核心MPLS网路带宽不说,这种洪泛攻击会给客户网络造成短时间的瘫痪。造成的损失极大。
在阐述Anycast防范DDOS攻击细节之前,让我们先来看看DDOS是如何产生的。
以NTP协议为例,NTP协议是client-server模式,客户发起NTP时间查询申请,服务器响应NTP查询。看似正常的NTP数据流量有时候及其容易被玩坏。
假设某个黑客控制了成千上万的僵尸主机,这些僵尸主机纷纷伪造如下数据包并发送给全球NTP服务器:
源地址:1.2.3.4 (伪造源地址为 被攻击者的IP地址)
目标地址:全球各个NTP服务器地址。(越多越好)
当全世界各地的NTP服务器收到此查询以后,它会把查询结果发送回给真正的受害者1.2.3.4。
这时IP地址为1.2.3.4 的受害者收到全世界的NTP服务器发过来的数据包时,其有限的带宽链路就很容易产生拥塞并造成服务中断。
假设这些僵尸不只是发送一次虚假数据包,而是上万次。
那么受害者接收到的NTP回复数据包量将如下:
虚假数据包发送数量 x 全世界NTP服务器的数量= 最终DDOS攻击的流量。
4.3.2. Anycast如何防范DDOS攻击?
好了,铺垫完成以后,回到正题。Anycast如何防范DDOS攻击?
DDOS攻击最关键一点,是需要把所有地理位置分散的小流量最终汇集到一个点。从而形成涛涛洪水。
正所谓以彼之道,还施彼身。
在Anycast环境下,由于多个地理位置不同的主机同时使用同一个IP地址。正因为如此,DDOS流量在穿越运营商路由器时,路由器会根据地理位置远近把数据包路由到距离源地址最近的受害者主机站点。从而分散掉整个DDOS流量。
还是以上述NTP协议DDOS为例。
假设IP为1.2.3.4的受害者恰巧布局了Anycast协议。其服务器分布在全国各地。
当DDOS来临时,不同的NTP服务器根据路由选择,把流量发送到距离NTP服务器最近的受害者服务器上。
最终,原本10Gbps-100Gbps的汇总流量被各个目标服务器以1Gbps不足的DDOS攻击消化掉。
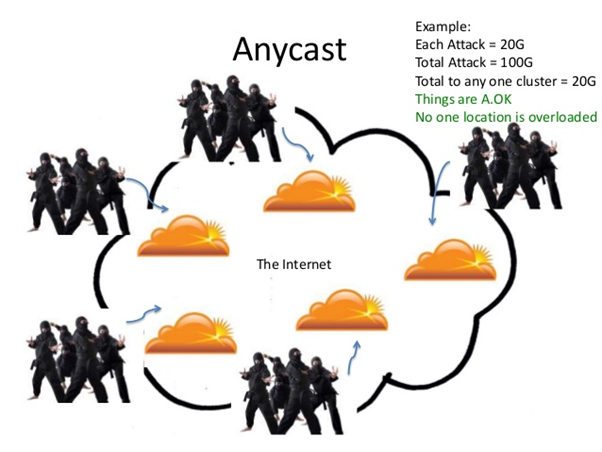
如上图所示,DDOS流量最终被每一个Anycast 主机分散掉了。
4.4. 内容分发网络(CDN)
Cloudflare作为CDN网络佼佼者,其主要采用了Anycast技术为用户提供距离用户最近的Cache服务器。从而大大提高了用户的服务体验满意度。
Cloudflare全球建设了118个数据中心,凭借于Anycast的高冗余性,正如本文开头提到的,任何一个数据中心出现网络、系统故障。均不会影响客户体验度,所有当地的客户流量会自动路由到其他就近的数据中心。
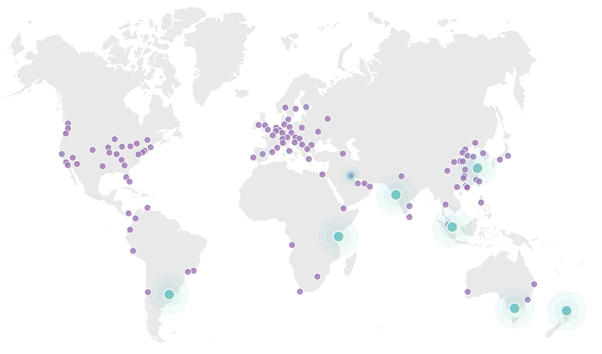
上图为Cloudflare的全球数据中心分布图
借助于Anycast的优势,相比传统企业网络面对网络节点故障的脆弱性,Cloudflare这方便就显得非常游刃有余了。
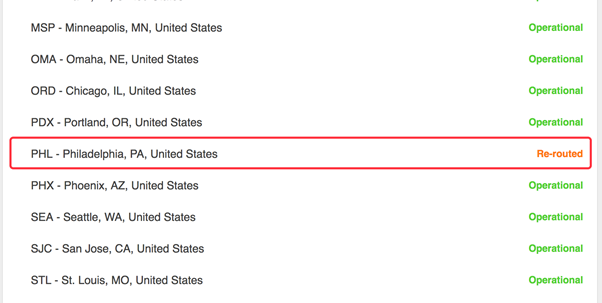
下面这张图为Cloudflare的部分数据中心Pop节点,请重点关注红框部分。
红框部分是美国-费城的一个数据中心节点,尾随其后有一个关键字“Re-routed”。
其含义为,此数据中心因为故障或者其他原因不能正常工作,所有费城的Cloudflare用户流量将会被自动路由到离费城最近的数据中心,无需人工干预。
看到这里,有些老鸟就禁不住想问。
Anycast是挺不错,但是看起来都是例如DNS,或者CDN在使用。
而且,无论是DNS服务提供商还是CDN服务提供商,他们最大的特点在于:每个Pop站点的服务器内容完全一样,所以客户无论访问站点A或者站点B,均能获取到相同的内容。
4.5. 数据中心(DCI)
4.5.1. 场景描述
LinkedIn大家最熟悉不过了,找工作攀人脉LinkedIn是经常去的地方。但是你可知道LinkedIn同样使用了Anycast技术。可是LinkedIn是纯粹的网页内容服务提供商。他与CDN,DNS提供商等性质不太相同。
而且大家需要注意的是,LinkedIn的流量可全是HTTPS,TCP流量。并非一般大家部署的DNS UDP流量。
那为什么LinkedIn也对Anycast如此感兴趣呢?
故事要从几年前说起。话说当LinkedIn业务急速扩展以后,出现了用户体验度差的问题,原因在于“时延”两个字。
因为数据中心地理位置固定,而用户位置可能是全世界各地。很自然,地理位置遥远的用户访问LinkedIn时会产生高时延问题。加上HTTP,HTTPS协议采用了话痨型的TCP协议。这TCP几次握手来回以后,加上后续HTTP数据流。本来时延就高的链接加上TCP信令数据包一来二去。用户体验度非常糟糕。
4.5.2. 解决方案
为了解决以上问题,LinkedIn引入小型数据中心站点(Pops)。在全世界有业务的地方构架小型DC。同时小型DC与美国总部的数据中心之间长期维持着稳定的TCP会话链接。
当远端用户访问LinkedIn后,TCP链接其实是发送给了当地的小型DC,小型DC再通过已有的TCP链接访问总部DC。从而大大减少了中间TCP信令会话的数量,变相降低了访问延时,提高了用户体验度。
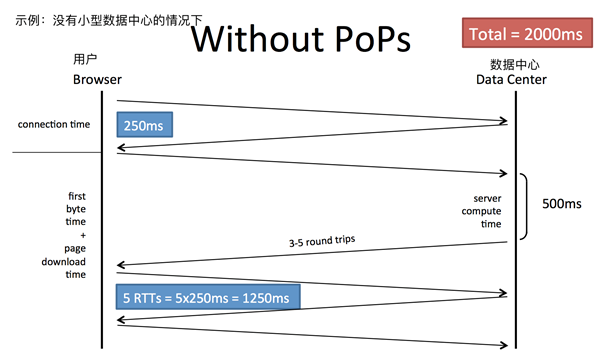
上图为,在没有小型数据中心的情况下,人机交互的流程以及时延。
下图为在用户所在地部署小型数据中心以后,时延的变化。
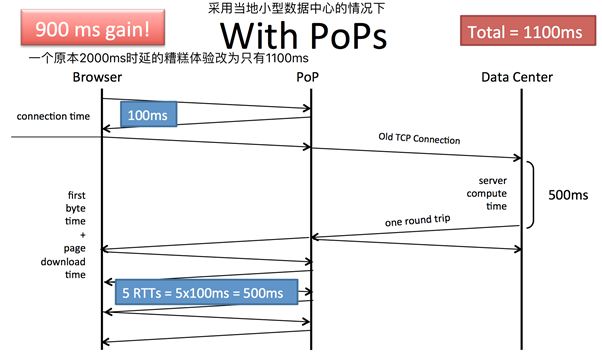
当LinkedIn在全世界范围内大批量部署小型DC以后,摆在他们面前的问题是,如何让用户能够就近访问当地的小型DC,而不是选择远端的数据中心总部?
这不就是Anycast擅长的么?对,LinkedIn也是这么想的,于是乎他们把整个美国的小型DC的IP地址修改为相同的IP,并通过BGP发布到Internet。
当用户访问LinkedIn时,DNS解析会返回此小型DC 的IP,然后用户运营商会根据就近原则路由用户数据到最近的小型DC。从而达到了上面所述的优化延迟的目的。
如下图所示,通过使用Anycast技术以后,LinkedIn小型DC访问命中率大大提高。
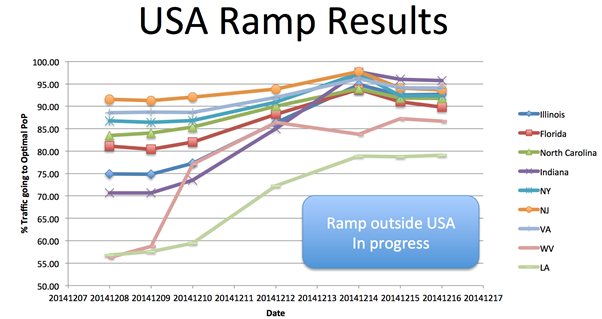
5. 参考文章
- Anycast简单总结 - 抟九 - 博客园 (cnblogs.com)
- Anycast技术
- 闲谈IPv6-Anycast以及在Linux/Win7系统上的Anycast配置
- ChinaNet和CN2介绍
- Public DNS+ 常见问题-DNSPod 技术支持-DNSPod-免费智能DNS解析服务商-电信_网通_教育网,智能DNS
- DNS多点部署IP Anycast+BGP实战分析_服务器应用_Linux公社-Linux系统门户网站
- 中文RFC文档目录
- 系统运维|DNS多点部署IP Anycast+BGP实战分析