1. 内部结构
1.1. 数组 Array
先说一下数组, 的确在 Go 语言中, 因为 slice 的存在, 使得 array 的出场率不高。但想要很好的理解 slice, 还是要先要了解 array.
Go 语言的数组和其他语言一样, 没有什么特别的地方, 就是一段以元素类型(如int)为单位的连续内存空间。数组创建时, 被初始化为元素类型的零值.
声明举例:
var arr [10]int // 长度为 10 的数组, 默认所有元素是 0
// len:10 cap:10 val:[0 0 0 0 0 0 0 0 0 0]
arr := [...]int{1, 2, 3} // 长度由初始化元素个数指定, 这里长度是 3
// len:3 cap:3 val:[1,2,3]
arr := [...]int{11: 3} // 长度为 12 的数组, 下标为11的arr[11] 初始化为 3, 其他为 0
// len:12 cap:12 val:[0 0 0 0 0 0 0 0 0 0 0 3]
arr := [5]int{1,2} // 长度为 5 的数组, 前两位初始化为 1, 2
// len:5 cap:5 val:[1 2 0 0 0]
arr := [5]int{1:2} // 长度为 5 的数组, 下标为1的arr[1]初始化为 2
// len:5 cap:5 val:[0 2 0 0 0]
arr := [...]int{1: 23, 2, 3: 22} // 长度为 4 的数组, 初始化为 [0 23 2 22]
// len:4 cap:4 val:[0 23 2 22]
[] 内设定数组长度, 写成 ... 表示长度由后面的初始化值决定.数组初始化的完整写法是 {1:23, 2:8, 3:12}, 只不过可以省略 index 写成 {23, 8, 12}, index 自动从 0 开始累加, 最大的 index 值决定数组长度.
如 {5: 10, 11, 12, 6: 100} 是非法的, 因为它会被转换成 {5: 10, 6: 11, 7: 12, 6: 100}, 会出现编译错误 duplicate index in array literal: 6.
1.2. 切片 Slice
slice 通常用来表示一个变长序列, 也是基于数组实现的。看下图:
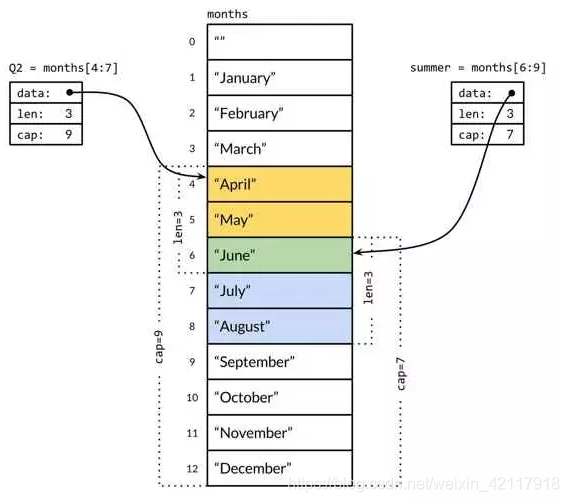
图中 Q2 和 summer 是 slice, 实际就是对数组 months 引用, 只是记录了引用了数组中的那些元素.
Q2的cap:13-4=9(length(months)-截取的前一个下标);summer的cap:13-6=7
再看一下 slice 在 Go 内部的定义
//D:\Program Files\Go\src\runtime\slice.go
type slice struct {
array unsafe.Pointer // 被引用的数组中的起始元素地址
len int // 长度
cap int // 最大长度
}第一个字段表示 array 的指针,是真实数据的指针第二个是表示 slice 的长度,第三个是表示 slice 的容量。所以 unsafe.Sizeof(切片)永远都是 24。
当把 slice 作为参数,本身传递的是值,但其内容就 byte* array,实际传递的是引用,所以可以在函数内部修改,但如果对 slice 本身做 append,而且导致 slice 进行了扩容,实际扩容的是函数内复制的一份切片,对于函数外面的切片没有变化。
package main
import (
"fmt"
"unsafe"
)
func main() {
slice_test := []int{1, 2, 3, 4, 5}
fmt.Println(unsafe.Sizeof(slice_test))
fmt.Printf("main:%#v,%#v,%#v\n", slice_test, len(slice_test), cap(slice_test))
slice_value(slice_test)
fmt.Printf("main:%#v,%#v,%#v\n", slice_test, len(slice_test), cap(slice_test))
slice_ptr(&slice_test)
fmt.Printf("main:%#v,%#v,%#v\n", slice_test, len(slice_test), cap(slice_test))
fmt.Println(unsafe.Sizeof(slice_test))
}
func slice_value(slice_test []int) {
slice_test[1] = 100 // 函数外的slice确实有被修改
slice_test = append(slice_test, 6) // 函数外的不变
fmt.Printf("slice_value:%#v,%#v,%#v\n", slice_test, len(slice_test), cap(slice_test))
}
func slice_ptr(slice_test *[]int) { // 这样才能修改函数外的slice
*slice_test = append(*slice_test, 7)
fmt.Printf("slice_ptr:%#v,%#v,%#v\n", *slice_test, len(*slice_test), cap(*slice_test))
}结果如下:
24
main:[]int{1, 2, 3, 4, 5},5,5
slice_value:[]int{1, 100, 3, 4, 5, 6},6,10
main:[]int{1, 100, 3, 4, 5},5,5
slice_ptr:[]int{1, 100, 3, 4, 5, 7},6,10
main:[]int{1, 100, 3, 4, 5, 7},6,10
24当append(list, [params]),先判断 list 的 cap 长度是否大于等于 len(list) + len([params]),如果大于那么 cap 不变,否则 cap = 2 * max{cap(list), cap[params]},所以当 append(numbers, 2, 3, 4) cap 从 2 变成 6。
1.3. 切片 Slice越界
slice 是可伸缩变长的, 导致很多人误以为 slice 是不会越界的, 下面我们来阐述下几种越界情况.
以上图中右侧的 summer 为例, summer[4] = "hello" 肯定会出现 index out of range 的 panic 信息, 尽管 cap(summer) = 7, 但 summer[4] 超出了 len(summer) = 3 的范围.
再看下面这个例子:
arr := [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(arr[:3:5][:4]) // [1 2 3 4]
fmt.Println(arr[:3:5][:8]) // panic: runtime error: slice bounds out of rangearr[:3:5] 基于 arr 创建一个 slice, len 是 3, cap 是 5; 然后再在这个 slice 的基础上分别创建一个 len = 4 和 len = 8 的 slice. 前者运行正常, 后者因超出 cap = 5 范围而 panic, 尽管后者实际想要的内存并没有超出 arr 数组范围.
对 slice 的操作记住两点:
- 数据直接访问(slice[index])时, index 值不能超过 len(slice) 范围
- 创建切片(slice[start:end])时, start 和 end 指定的区间不能超过 cap(slice) 范围
- 创建一个 slice := make([]int, 5, 10), 然后 slice[8] 和 slice[:8] 的运行结果是什么? slice[8] 会 panic, 而 slice[:8] 正常返回.
2. 申请方式和初始化方式不同
// 数组在创建时,需指定最大存放的元素个数
var array = [5]int{1, 2, 3, 4, 5}
var array = [5]int{}
// 切片
var slice = []int{1, 2, 3, 4, 5} // 创建cap=5,len=5,并初始化的slice
var slice = make([]int, 0, 5) //创建cap=5,len=0的slice
var slice = make([]int, 5) // 创建cap=5,len=5的slice3. 长度为 0
3.1. 数组 Array
比较特别的就是 [0]int, 长度为 0 的数组. 这种不占有任何内存空间的数据类型实际上是无意义的, 所以 Go 语言对此类数据特殊处理了一下, 此外还包括 struct{}, [10]struct{} 等。
var (
a [0]int
b struct{}
c [0]struct {
Value int64
}
d [10]struct{}
e = new([10]struct{}) // new 返回的就是指针
f byte
)
fmt.Printf("%p, %p, %p, %p, %p, %p", &a, &b, &c, &d, e, &f)
//运算结果 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0x1127a88, 0xc42000e280前 5 个变量的内存地址一样, 第 6 个变量 f 有一个真实可用的内存. 也就是说 Go 并没有为 [0]int 和 struct{} 这类数据真正分配地址空间, 而是统一使用同一个地址空间.
这类数据结构在 map 中经常应用, 比如 map[string]struct{}. 声明这样一个 map 类型来标记某个 key 是否存在. 在 key 值很多的情况下, 要比 map[string]bool 之类的结构节约很多内存, 同时也减小 GC 压力.
3.2. 切片 Slice
- 值为 nil 的 slice 变量的 len 和 cap 都是 0. 虽然它没有指向具体某个数组(slice.array 为空), 但是它的 slice.len 和 slice.cap 默认就是 0.
4. 作为函数参数
- func(arr []int) 这种函数对参数 arr 的修改, 会影响到外面数值, 因为函数内部操作的内存与外界是同一个. 这是 slice 和 array 的主要区别之一。slice看起来像个引用传递,原因是,在slice的结构内部有一个指向底层数组的指针,slice的下标取值,通过类似C语言指针取值的方式,实际操作底层数组。
func arrayslice3() {
var slice = []int{1, 2, 3, 4, 5, 6, 7, 8}
var array = [8]int{1, 2, 3, 4, 5, 6, 7, 8}
change_arr1(slice)
change_arr2(array)
fmt.Println("slice1 = ", slice) //[10,2,3,4,5,6,7,8]
fmt.Println("array = ", array) //[1,2,3,4,5,6,7,8]
}
func change_arr1(arr []int) { //切片会改变内部数值
arr[0] = 10
fmt.Println("arr = ", arr) //[10,2,3,4,5,6,7,8]
}
func change_arr2(arr [8]int) { //数组不会改变内部数值
arr[0] = 10
fmt.Println("arr = ", arr) //[10,2,3,4,5,6,7,8]
}5. 扩容性
- 数组一开始已定义好连续内存,之后再分配很难。
- 如果使用切片,其扩容性将大大提高。当slice的cap不够时,将自动扩容,扩容后的slice可能与原来的slice地址不一样。
var slice = make([]int, 3,5)
slice = append(slice, 1)5.1. 切片拷贝例1
append 会让切片和与他相关的切片脱钩,但地址不变;
func slice6() {
a := []int{1, 2, 3, 4}
b := a
printSlicePrefix(a, "part1 a")
printSlicePrefix(b, "part1 b")
fmt.Printf("\n")
a[0] = 9
printSlicePrefix(a, "part2 a")
printSlicePrefix(b, "part2 b")
fmt.Printf("\n")
a = append(a, 5)
a[0] = 1
printSlicePrefix(a, "part3 a") //因为构造新的内存空间,所以整体拷贝新的地址空间并全部复制
printSlicePrefix(b, "part3 b")
fmt.Printf("\n")
c := a
d := &a
printSlicePrefix(a, "part4 a")
printSlicePrefix(c, "part4 c")
printSlicePrefix(c, "part4 d")
fmt.Printf("\n")
a = append(a, 6)
printSlicePrefix(a, "part5 a")
printSlicePrefix(c, "part5 c")
printSlicePrefix(*d, "part5 *d")
}
/*输出结果:
part1 a len=4 cap=4 slice=[1 2 3 4]
part1 b len=4 cap=4 slice=[1 2 3 4]
part2 a len=4 cap=4 slice=[9 2 3 4]
part2 b len=4 cap=4 slice=[9 2 3 4]
part3 a len=5 cap=8 slice=[1 2 3 4 5]
part3 b len=4 cap=4 slice=[9 2 3 4]
part4 a len=5 cap=8 slice=[1 2 3 4 5]
part4 c len=5 cap=8 slice=[1 2 3 4 5]
part4 d len=5 cap=8 slice=[1 2 3 4 5]
part5 a len=6 cap=8 slice=[1 2 3 4 5 6]
part5 c len=5 cap=8 slice=[1 2 3 4 5]
part5 *d len=6 cap=8 slice=[1 2 3 4 5 6]
*/5.2. 切片拷贝例2
// 每次cap改变,指向array的ptr就会变化一次
s := make([]int, 1)
fmt.Printf("len:%d cap: %d array ptr: %v \n", len(s), cap(s), *(*unsafe.Pointer)(unsafe.Pointer(&s)))
for i := 0; i < 5; i++ {
s = append(s, i)
fmt.Printf("len:%d cap: %d array ptr: %v \n", len(s), cap(s), *(*unsafe.Pointer)(unsafe.Pointer(&s)))
}
fmt.Println("Array:", s)以上代码执行输出结果为:
len:1 cap: 1 array ptr: 0xc8200640f0
len:2 cap: 2 array ptr: 0xc820064110
len:3 cap: 4 array ptr: 0xc8200680c0
len:4 cap: 4 array ptr: 0xc8200680c0
len:5 cap: 8 array ptr: 0xc82006c080
len:6 cap: 8 array ptr: 0xc82006c080
Array: [0 0 1 2 3 4]
- 大概解释:每次cap改变的时候指向array内存的指针都在变化。当在使用 append 的时候,如果 cap==len 了这个时候就会新开辟一块更大内存,然后把之前的数据复制过去(实际go在append的时候放大cap是有规律的。在 cap 小于1024的情况下是每次扩大到 2 cap ,当大于1024之后就每次扩大到 1.25 cap 。所以上面的测试中cap变化是 1, 2, 4, 8); 但是这么说也不完全准确,需要根据具体情况决定。见下一章append数据空间申请。
5.3. append函数深入理解
append函数的数据空间申请
var numbers []int
printSlice(numbers)
/* 允许追加空切片 */
numbers = append(numbers, 0)
printSlice(numbers)
/* 向切片添加一个元素 */
numbers = append(numbers, 1)
printSlice(numbers)
/* 同时添加多个元素,自动扩容为2的整数倍 */
numbers = append(numbers, 2, 3, 4) //2<5
printSlice(numbers)
/*结果
len=0 cap=0 slice=[]
len=1 cap=1 slice=[0]
len=2 cap=2 slice=[0 1]
len=5 cap=6 slice=[0 1 2 3 4]
len=5 cap=12 slice=[0 1 2 3 4]
*/- 问题:len=5 cap=6 slice=[0 1 2 3 4].为什么这里的 cap 不是 5 呢?答案请往下看
5.4. 扩容原理
可以通过查看$GOROOT/src/cmd/compile/internal/gc/walk.go $GOROOT/src/runtime/slice.go 源码,其中扩容相关代码如下,调用顺序依次appendslice中调用growslice:
func appendslice(n *Node, init *Nodes) *Node {
//...
// s = l1
// n := len(s) + len(l2) //1. 这里 nn = 原切片长度+新切片长度
// if uint(n) > uint(cap(s)) //2. 判断新切片nn长度是否大于原切片长度
// instantiate growslice(typ *type, []any, int) []any
fn := syslook("growslice")
fn = substArgTypes(fn, elemtype, elemtype)
// s = growslice(T, s, n) //3.这里触发growslice函数增加空间
nif.Nbody.Set1(nod(OAS, s, mkcall1(fn, s.Type, &nif.Ninit, typename(elemtype), s, nn)))
nodes.Append(nif)
//...
}
func growslice(et *_type, old slice, cap int) slice {
//...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
//...
switch {
case et.size == sys.PtrSize:
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
capmem = roundupsize(uintptr(newcap) << shift)
newcap = int(capmem >> shift)
default:
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
newcap = int(capmem / et.size)
}
//指定分配内存大小通用值,对于系统指针,编译器将通过乘除法优化到一个常量;
switch {
//...
case et.size == sys.PtrSize: //指针大小8(64位系统)
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
newcap = int(capmem / sys.PtrSize)
//...
}
//...分配内存,然后slice(结构体)...
return slice{p, old.len, newcap}
}
//具体的扩容逻辑
// Returns size of the memory block that mallocgc will allocate if you ask for the size.
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize { //_MaxSmallSize==32768
if size <= smallSizeMax-8 { //smallSizeMax=1024-8 smallSizeDiv=8 largeSizeDiv=128
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
///...
return alignUp(size, _PageSize)
}
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
// divRoundUp returns ceil(n / a).
func divRoundUp(n, a uintptr) uintptr {
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}从上面的代码可以看出以下内容:
-
步骤一:appendslice中比较参数
append 发生扩容时,原有切片长度简述为l1,容量c;添加切片长度l2;则新申请容量是n = l1 + l2;
当新申请容量n大于原有切片容量c时,调用growslice函数; -
步骤二:growslice
首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。 -
步骤三:roundupsize向上取整大小函数
在这里进行扩容大小的计算,传入参数为bit。如果申请空间为5字节40bit,则入参size uintptr值为40;
接着调用了 roundupsize 函数,et.size=8,传入 40,所以divRoundUp返回为= 5;获取 size_to_class8 数组中索引为 5 的元素为 5;获取 class_to_size 中索引为 5 的元素为 48,roundupsize 返回48,表示比特大小。
最终,新的 slice 的容量为 6